摘要:公告的第一页网址如下:https://bigonepage=1#articles对应的页面如下:公告列表第1页公告的第二页网址如下:https://bigonepage=2#articles公告的第3页网址如下:https://bigone...
在当今这个时代,投资可以说是每个人都应该学会的一项技能。拥有一些数字货币是程序员的信仰!交易所是进入数字货币世界最方便的一扇门,今天我就带着大家爬取 Bigone 交易所的公告数据。
首先,我们来看一下要爬取的页面以及对应的网址。
公告的第一页网址如下:
https://bigone.zendesk.com/hc/zh-cn/sections/115000476773?page=1#articles
对应的页面如下:
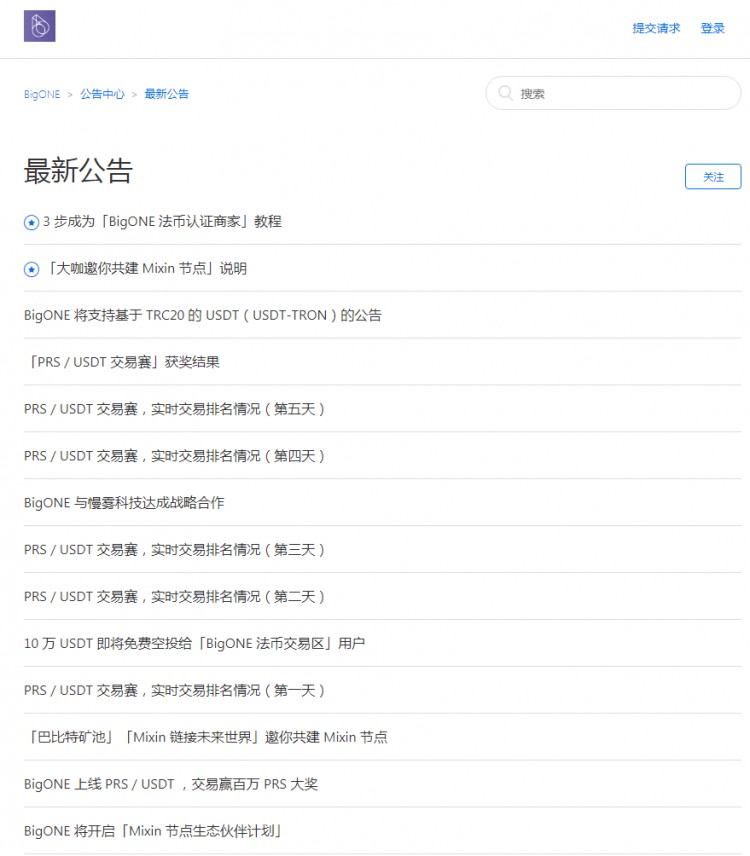
公告列表 第1页
公告的第二页网址如下:
https://bigone.zendesk.com/hc/zh-cn/sections/115000476773?page=2#articles
公告的第3页网址如下:
https://bigone.zendesk.com/hc/zh-cn/sections/115000476773?page=3#articles
观察每一页的网址,我们发现参数page的赋值表示所要爬取的页码。这样所要爬取的网址就搞定了。
这里需要注意一个问题:从请求的网址来看,数据的传输通过https协议,这个协议通常使用 SSL 密码学协议。但这个网站使用的是 TLS1.2 密码学协议。开始写这块代码的时候没有留意,结果抛出 “请求被中止: 未能创建 SSL/TLS 安全通道”异常。耗费了很大的精力才知道是这块出了问题。
然后,我们来看网页的源码。
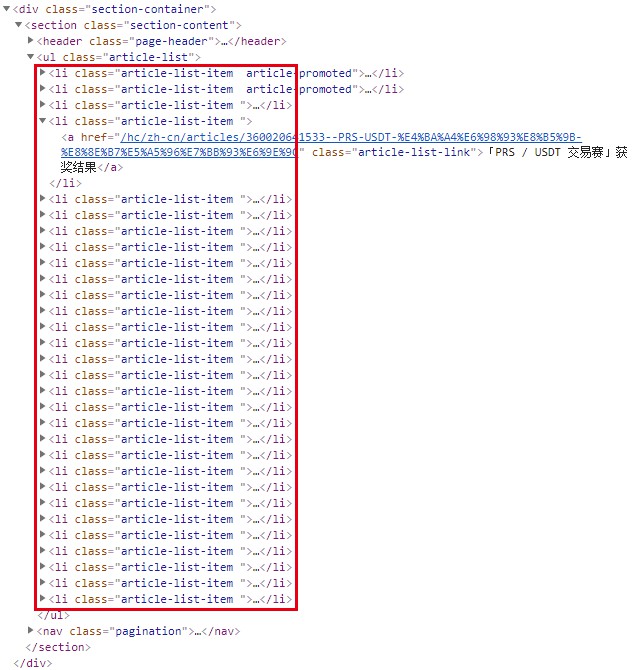
源码 article-list 类
从网页的源码中我们发现所要的公告数据全部存储于 article-list 类的 a 标签中。
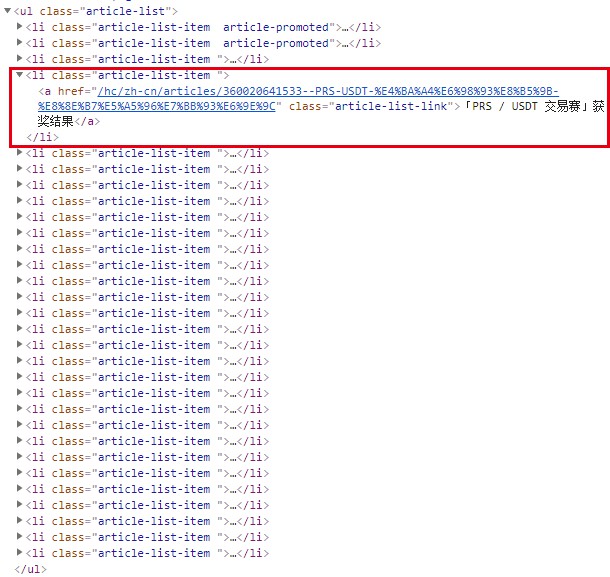
源码 a 标签
在 a 标签中,我们可以看到公告的标题,以及公告对应的详细网址。但是,没有该公告发布的时间。
接着,我们请求该公告对应的网址,得到网页的源码如下:

源码 time标签
通过这份源码,我们发现在 time 标签中我们可以得到该份公告发布的时间。这样,我们需要的数据就全部拿到了。
最后,我们用 Jumony 这套开源代码来获取网页对应的 HTML DOM TREE ,这套开源代码可以在 Github 上下载。下载地址为:
https://github.com/Ivony/Jumony
Jumony下载
这里对 Jumony 就不做过多介绍了,要是大家感兴趣,可以在图文下方留言,我后面再写几篇图文来介绍这个工具。
找到了所要爬取的网页地址,分析完网页的源码,确定了所用的工具和技术路线,剩下的就是写代码进行实现了。
Step1. 创建一个公告类的结构 Announcement
public class Announcement
{
/// <summary>
/// 交易所名称
/// </summary>
public string ExchangeName;
/// <summary>
/// 公告时间
/// </summary>
public string Time;
/// <summary>
/// 公告标题
/// </summary>
public string Title;
/// <summary>
/// 公告网址
/// </summary>
public string Url;
/// <summary>
/// 格式化 Announcement 输出
/// </summary>
/// <returns></returns>
public override string ToString()
{
if (string.IsNullOrEmpty(Time))
return base.ToString();
DateTime dt = DateTime.Parse(Time);
string result = "[" + dt.Year + "/" + dt.Month + "/" + dt.Day
+ " " + Title.Trim() + "](" + Url + ")";
return result;
}
}
Step2. 获取对应网址的 HTML DOM TREE
public static IHtmlDocument GetHtmlDocument(string url)
{
IHtmlDocument document;
try
{
ServicePointManager.SecurityProtocol = SecurityProtocolType.Tls12;
document = new JumonyParser().LoadDocument(url);
}
catch
{
document = null;
}
return document;
}
public static IHtmlDocument GetHtmlDocument(int page)
{
string url = "https://bigone.zendesk.com/hc/zh-cn/sections"
+ "/115000476773?page="
+ page
+ "#articles";
return GetHtmlDocument(url);
}
Step3. 获取公告列表 List<Announcement>
public static List<Announcement> GetBigOneAnnouncement(int page)
{
List<Announcement> result = new List<Announcement>();
IHtmlDocument doc = GetHtmlDocument(page);
if (doc == null)
return result;
List<IHtmlElement> lists = doc.Find(".article-list a").ToList();
for (int i = 0; i < lists.Count; i++)
{
Announcement announcement = new Announcement();
announcement.ExchangeName = "Bigone";
announcement.Title = lists[i].InnerHtml();
string url = "https://bigone.zendesk.com"
+ lists[i].Attribute("href").AttributeValue;
IHtmlDocument temp = GetHtmlDocument(url);
announcement.Url = temp.DocumentUri.ToString();
List<IHtmlElement> t = temp.Find("time").ToList();
announcement.Time = t[0].InnerHtml();
result.Add(announcement);
}
return result;
}
Step4. 获取 Markdown 格式化文本
private string GetReport(List<Announcement> lst)
{
if (lst == null || lst.Count == 0)
throw new ArgumentNullException();
string result = Environment.NewLine+ "**"
+ lst[0].ExchangeName + "**" + Environment.NewLine;
for (int i = lst.Count - 1; i >= 0; i--)
{
result += "- " + lst[i] + Environment.NewLine;
}
return result;
}
Step5. HTML渲染格式化输出文本
private void ShowMarkdownData(string str)
{
string temp = Environment.GetEnvironmentVariable("TEMP");
temp += "\\Announcements.txt";
StreamWriter sw = File.CreateText(temp);
sw.Write(str);
Process.Start(temp);
sw.Close();
}
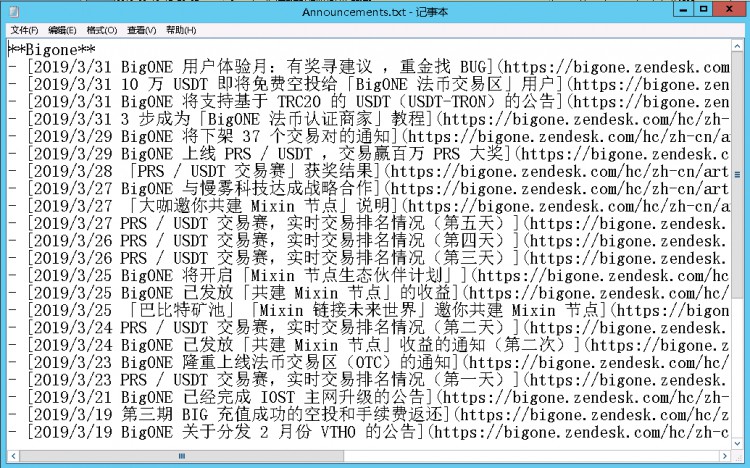
Markdown文本
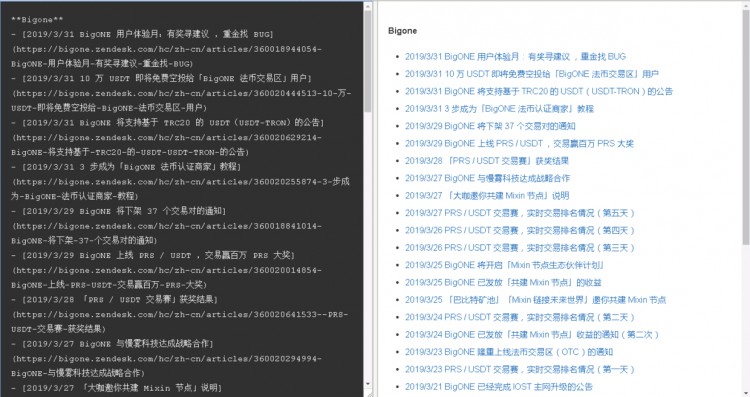
HTML渲染
到此为止,如何利用 C# 爬取 BigOne 交易所的公告就全部介绍完了。本文以及前几天哪篇 [如何利用 C# 爬取 Gate.io 交易所公告]的图文都是为了 自动化 每周日的 [「股市币市:本周交易数据分析与最新公告」],所以我做了一个 winform 以方便管理。
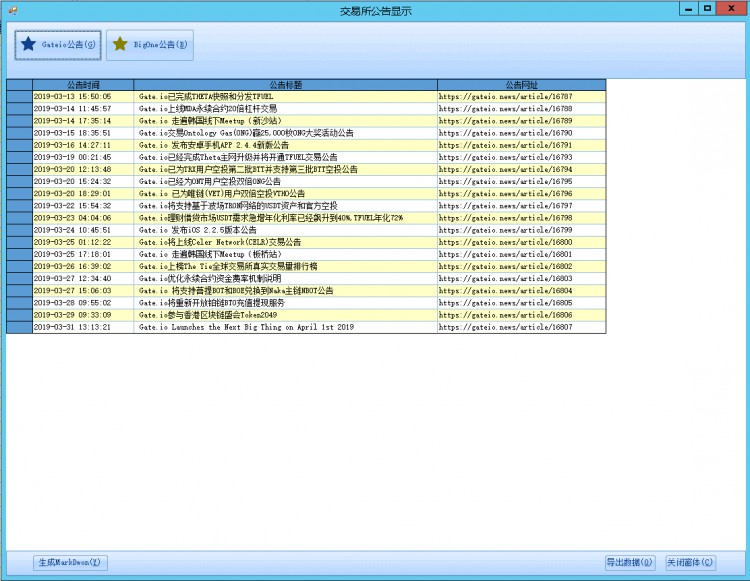
winform gateio
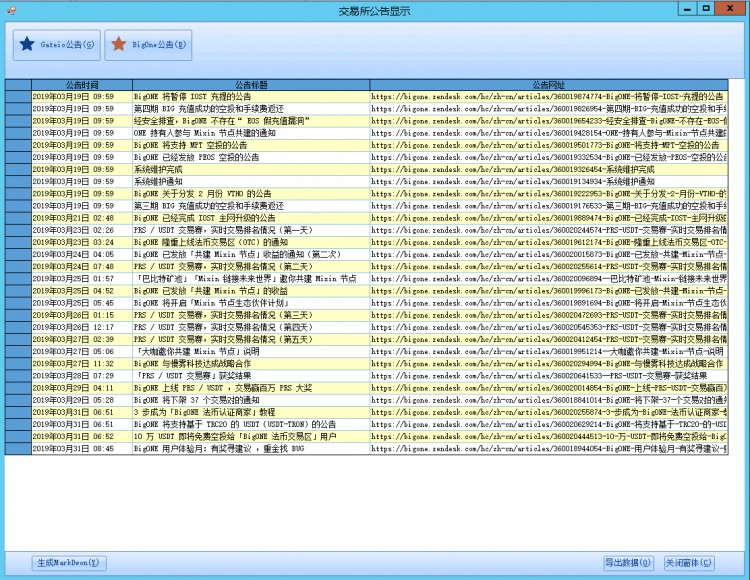
winform bigone
学一项技能,就要“以我为主,为我所用”,很多时候都是有一个想法,想想需要什么技能,想好后就去学了。中间遇到困难,不逃避,勇敢面对,干掉它就好。今天就到这里吧!See You!